오늘로서 핀토스 운영체제를 마쳤다.
핀토스를 하며 느낀점에 대해서는 다음 포스팅에 작성하겠다. (아마 매우 길어질 것 같아서)
이번 포스팅은 핀토스 운영체제 프로젝트의 지옥주 3주차인 가상 메모리 VM에 대해 작성하겠다.
구현하느라 바쁘게 달려온 오늘로 마무리된 2주의 기간동안
구현과 고민을 하는 순간 순간의 감정과 생각들의 기록을 전부 남겨보려고 한다.
좀 길어진다면 여러개의 포스팅으로 나누어 작성하겠다.
메모리 관리
처음 메모리 관리를 들어갔을 때 3일 정도 고민했던 사항이 바로 이 메모리 관리에 관해서이다.
깃북을 처음 읽었을 때, 다음처럼 spt(supplemental page table)이라는 것을 추가 구현해야 한다고 나와있었다.

지금까지 코드 상에서 pml4(page map level 4 : page table)의 내용을 직접적으로 꺼내거나 집어넣는 내용은 없었다.
딱 한가지 다뤄본 것이 프로세스를 fork()하는 시스템콜을 구현할 때, pml4_set_page로 새로 생성한 자식의 메모리 페이지를 pml4에 등록하는 것만 스쳐 지나갔었는데, 이는 이미 작성되있던 default code 였기에 크게 신경쓰지 않았다.
그래서 pml4가 정확히 어떤 역할을 하는지 모른채로, CS:APP 책에서 공부했던 "페이지 테이블의 역할을 하는구나" 라고 생각했다.
그래서 고민했던 질문은
"핀토스에서는 pml4가 페이지테이블 역할을 하고 있는데 왜 보충 페이지가 필요한가?"
였다.
pml4에는 ispresent 비트 , access 비트, dirty 비트의 내용을 통해 메모리가 있는지, 접근했는지, 수정됬는지 알 수 있다.
근데 왜 spt가 필요한가?
그 이유는 process_exec() 함수에서 실행 파일을 로드하는 코드에서 확인할 수 있었다.
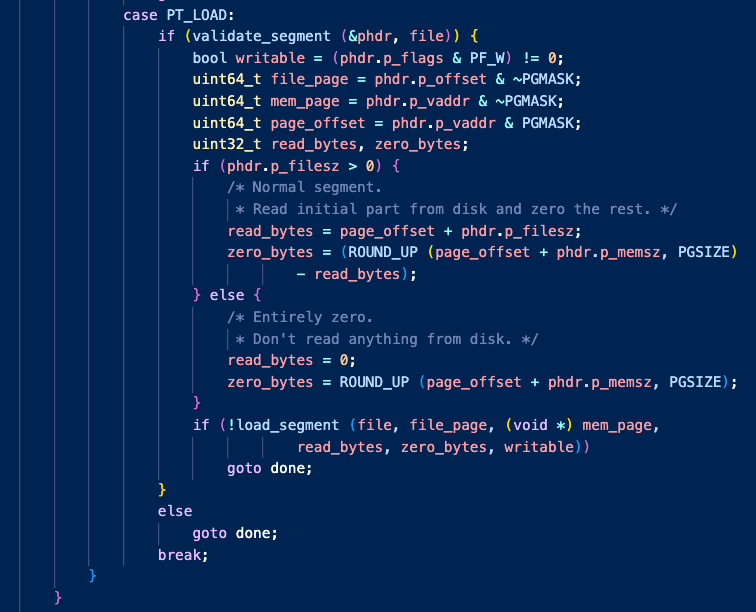
load 함수의 내부 구조를 찬찬히 보니 전혀 알 수 없는 flag 사이에 load_segment라는 함수가 보였다.
이 함수는 2주차 userprog를 구현할 때, 하단에 VM과 USERPROG 주차가 define 커맨드로 구분되어 있었다.
VM 에서 spt가 왜 필요한지 확인하기 위해 해당 함수들을 뜯어봤다.

이 함수는 lazy_loading하고 있지 않다.
이 함수는 유저 pool의 PGSIZE 물리 메모리 할당을 요청하고 로딩할 파일을 읽어서 옮기고,
(난 이때까지 palloc_get_page가 pintos만의 malloc() 요청인줄 알았다.)
install_page라는 함수를 통해 pml4에 방금 할당받은 페이지를 등록한다.
이때 깨달았다.
lazy_loading 방식으로 메모리를 관리하면 실제로 물리 메모리를 할당하지 않고 할당한 척만 하니까, pml4에 등록할 수 없다.
" 그럼 할당한 척만 한 메모리들과 할당한 척도 하지 않은 메모리들은 어떻게 구별하나? == SPT 테이블로 ! "
따라서 VM 주차의 load_segment() 함수는 다음처럼 달라진다.
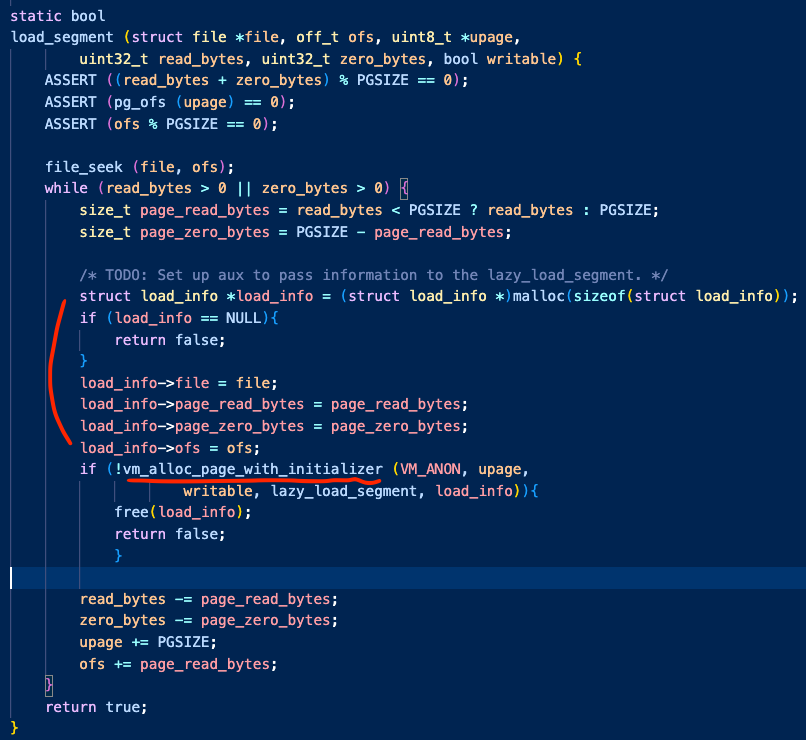
이 함수에서 달라진 점은 총 두가지이다.
1. palloc_get_page()으로 물리메모리를 요청한 뒤 pml4에 set하지 않고 -> spt에 가상의 페이지를 담는 것으로 대체
2. 현재 페이지의 담겨야 하는 내용들을 malloc에 저장하여 spt에 담는 페이지에 전달
1번은 vm_alloc_page_with_initializer() 함수가 수행한다.
이 함수는 이후 mmap() 시스템 콜을 통해 파일 메모리 맵핑 페이지의 유형도 같이 처리하기 위해
페이지의 타입을 첫번째 인자로 받는다.
현재 프로그램을 실행하기 위한 데이터와 코드의 메모리 적재는 anonymous 유형의 페이지이다.
처음 load_segment함수에서 vm_alloc_page_with_initializer에 유형 인자를 anon으로 전달하여 가상의 페이지를 생성하지만
사실 vm_alloc_page_with_initializer를 통해 생성되는 유형은 사실 anon이 아니라 uninit이다.
(이걸 깨닫는데 4일정도 걸린 것 같음)
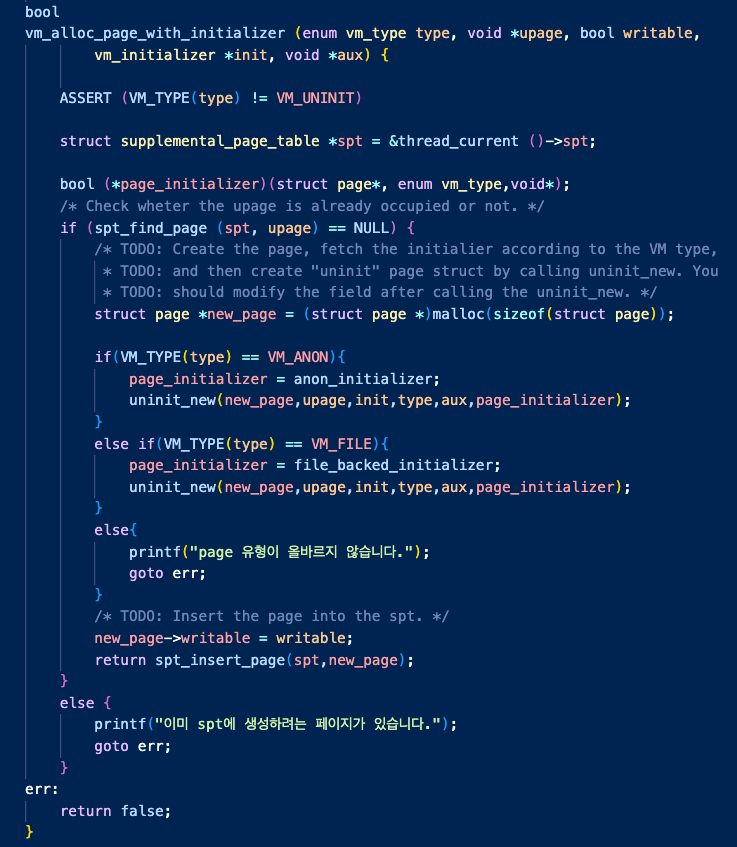
지금은 구현하여 다 채워져 있지만, 이때 당시에 이 함수는 무엇을 하는 기능인지 설명하는 주석을 빼면 거의 비어있었다.
이 함수는 uninit 페이지를 생성하는데, uninit의 의미는 아직 물리 메모리를 할당받지 않은 상태라는 의미이다.
따라서 uninit 페이지의 구조체에는 page_fault가 발생하여 page를 lazy_loading해야 할 때
이 페이지가 어떤 유형의 페이지인지, 뒤늦게 로드되는 구현 함수의 포인터는 어디인지, 어떤 내용을 읽어야 하는지, 어디서 얼마나 읽어야 하는지에 대한 내용을 담고 있어야 했다.
그래서 aux 인자를 통해 load_segment()에서 만든 load_info 구조체를 전달했고
unint을 만드는 uninit_new() 함수를 통해 가상의 struct uninit page를 생성하여 spt에 insert하였다.
이렇게 하면 이제 커널이 process를 실행하기 위해 로드하는 전조 작업은 끝이 난다.
이제 실행 프로세스가 실행중에 물리 메모리에 로드된줄 알고 참조하여 page_fault가 일어나기만 기다리면 된다.
정리하면 여기까지의 작업은 모두 유저 프로그램이 실행되도록 컨텍스트가 유저 프로그램으로 스위칭 되기 전의 작업이다.
load로 물리 메모리를 직접 주는 대신 vm_alloc_page_initializer를 통해 가상의 페이지 구조체를 spt 테이블에 집어넣었다.
PAGE_FAULT 후 처리 구현
이제 page_fault가 발생하는 함수를 들여다보자.

page_fault() 함수는 페이지 폴트를 일으킨 주체가 누구인지(user), 페이지 폴트가 물리메모리가 존재하지 않아서 발생한 페이지 폴트인지(is_present), 페이지 폴트가 일어난 주소가 쓰기가능인지(writable) 에 대해 pml4 entry flag bit를 통한 정보를 전달한다.
(pte의 flag bit에 대한 정보는 운영체제 4가지 책을 읽어보면 자세히 나와있다.)
이때 이 page_fault를 일으키게 하는 주체도 사실 이때는 잘 몰랐지만
카이스트 권영진 교수님의 강의를 통해 하드웨어 시스템인 pml4 테이블이 page_fault()를 일으킨다는 사실을 알게 되었다.
따라서 CPU를 점유한 프로세스의 pml4 테이블과 비교하여 set 되어있지 않다면 page_fault()를 일으킨다.
지난 주차까지는 page_fault가 발생하면 무조건 잘못된 참조였지만 lazy_loading을 사용한 이유로는 아니다.
물리 메모리를 할당한 척했기 때문에 물리 메모리가 없을 수 있고,
vm_try_handle_fault()을 통해서 정당한 page_fault인지 판단해야 했다.
- stack_growth
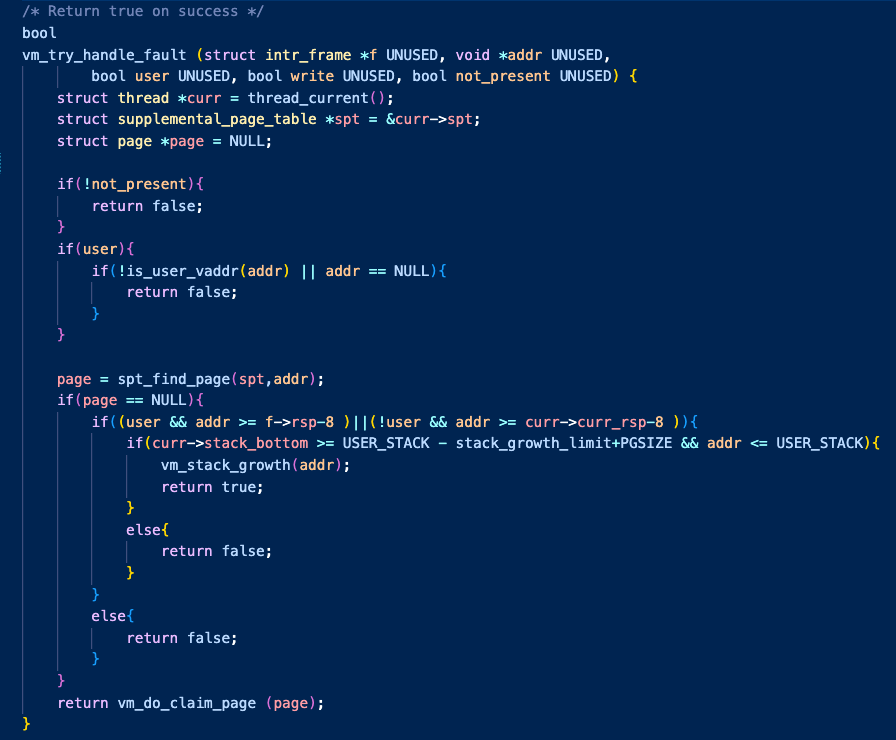
이 함수안에서는 deny 해야하는 불법적인 page_fault는 false 를,
정당한 페이지 폴트는 vm_do_claim_page()로 내려간다.
여기서 매우 더럽게 짜져있는 세번째 if문은 stack growth 를 위한 예외 처리이다.
나는 개인적으로 또 다른 정당한 예외 page fault 상황인 stack growth가 가장 개념적으로 이해하기 어려웠다.
(깃북이 이 개념에 대해 많이 불친절하기도 했음)
깃북말고는 챗지피티는 물론 다른 블로그도 참조하지 않겠다는 괜한 고집때문에 이 부분에 대해 고민을 굉장히 많이했다.

처음에 이 깃북을 보고는
'경험적 방법을 고안하십시오?'
'사용자 프로그램이 rsp를 전달해준다. 하지만 전달된 값을 읽으면 정의되지 않은 값이 생성된다.'
이게 뭔 쌉소리지?
이후 런타임 스택에 대해 공부했던 이론을 적용해보려고 생각해보았다.
유저 프로그램은 함수를 호출하기 전에 스택영역에 담아 함수에 인자를 전달한다.
이때 만약 긴 재귀상황이 발생하거나, 호출할 함수에 많은 인자 데이터를 전달해야 할 경우
처음 load 시 할당해준 1페이지 영역 이상을 초과할 수 있다.
이때, 이 경우는 spt에 존재하는 페이지 주소도 아닌 주소영역이기 때문에
예측할수 없는 스택 연장에 대한 특별한 상황이 발생하면 이를 rsp를 이용하여 감지하도록 하고 예외처리를 해줘야 한다는 말이다.
근데 이때, 만약에 사용자가 system call을 요청하여 커널로 문맥이 전환된 후에
system call 작업 중에 page_fault가 발생했을 경우
문맥이 전환되었기 때문에 시스템 콜을 요청한 사용자의 rsp(스택포인터)를 전달받지 못한다는 뜻이다.
따라서 system call을 요청받은 즉시 사용자의 rsp를 기억하도록 스레드 멤버에 저장해뒀다가(내 코드 상에선 curr_rsp)
이를 page_fault가 발생했을 때 참조해보면 된다.
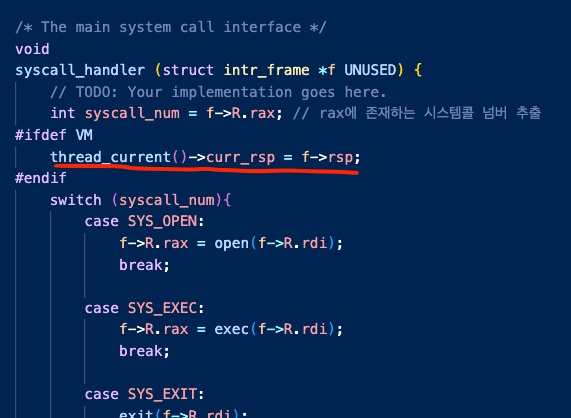
따라서 다음처럼 위 사진처럼 syscall 요청받은 커널은 즉시 사용자 인터럽트 프레임으로부터 rsp를 전달받도록 했다.

원래 page_fault가 발생했을 때, spt에도 로드되기로한 페이지가 없으면 무조건 false였지만
스택확장의 경우를 고려하기 위해 rsp를 내리면서 스택을 쌓고있었는지 확인해보고
만약 rsp가 스택을 쌓고 있는 범위 내 주소에서 page_fault가 발생했다면
스택을 확장해주도록 했다.
(체크된 곳은 스택의 최대 한도를 1MB로 두고 그 안에 주소가 들어가는지 확인했다.)
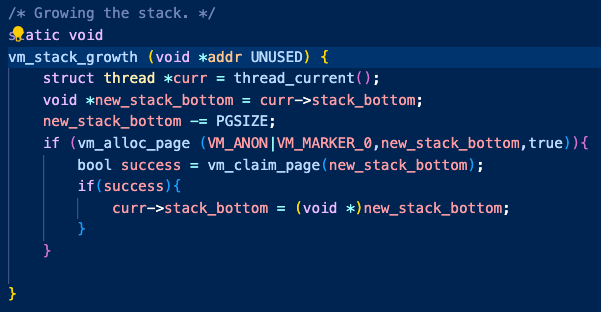
그리고 이후 stack_growth 코드를 작성했다.
이 코드는 setup_stack과 거의 동일하게 짜면 되었다.
thread는 현재 진행중인 프로세스의 stack_bottom 주소를 기억하게 했고,
이를 통해 어디를 스택 확장해주어야하는지 추출해 내도록 했다.
- lazy loading
만약 잘못된 모든 예외상황을 제외하면 (+ stack growth 예외 상황까지 제외하면)
해당 페이지 폴트는 lazy loading을 위한 합법적인 페이지 폴트라는 것이 확인된다.
그럼 이제 실제로 demanding 된 페이지를 load 하는 flow를 살펴보자.
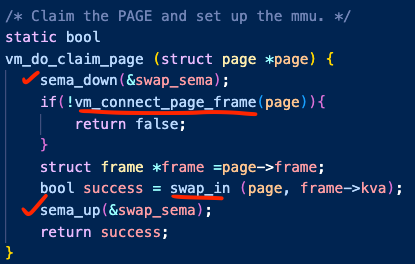
demanding page fault 라면 위 사진의 함수로 올것이다.
세마포어는 frame에서 넣고 빼는 작업을 단일화 하기 위해 해당 작업에 넣었다.
만약 frame으로부터 빼고 다른 페이지가 넣으면 문제가 발생할 것이라 예상했다.
이후 파일이나 anon 페이지를 프레임으로 올리는 swap_in 함수에에서는 공간이 있다고 판단하고 작업을 진행하기 때문에 동기화를 꼭 사용해줘야만 했다.
그전에 먼저 vm_connect_page_frame을 통해 frame 퇴거 정책을 통해 frame에 공간을 마련하도록 했다.
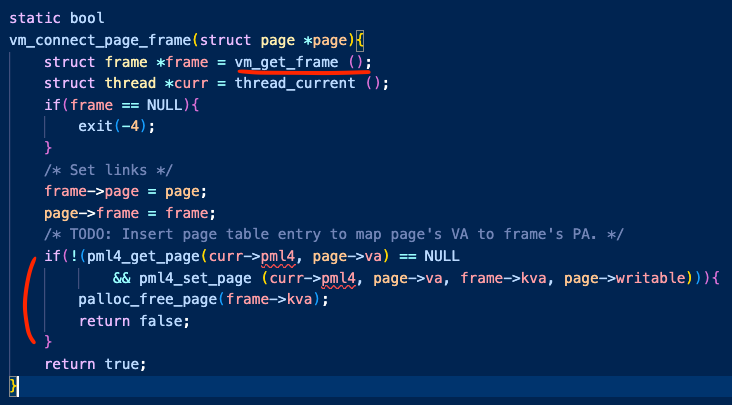
위의 사진은 vm_connect_page_frame() 이다. vm_get_frame() 함수를 통해 퇴거 정책을 수행하는 함수로 들어간다.
퇴거가 끝난 후 frame과 page를 연결하고 pml4에 set하도록 했다.
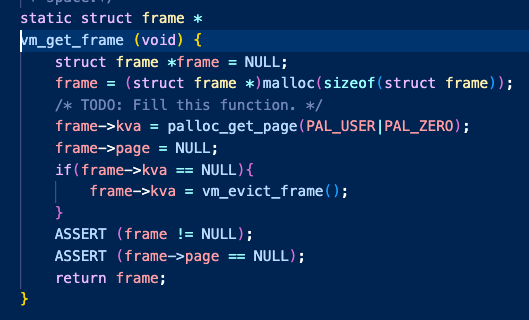
vm_get_frame 함수에서는 새로운 frame 구조체 데이터 공간을 malloc으로 요청한 뒤
물리 메모리 주소인 kva에 palloc_get_page로 요청한다.
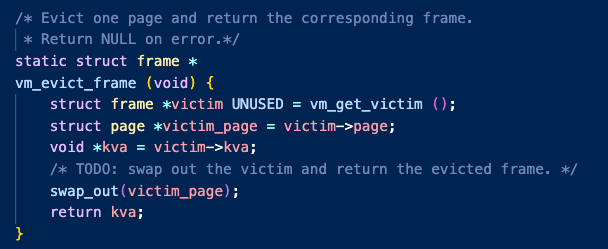
만약 자리가 없어서 NULL을 반환한다면 evict_Frame을 통해 퇴거 정책 함수로 들어간다.

이 함수에서 굳이 퇴거 정책을 구현해도 됬지만,
다른 퇴거 정책도 테스트해볼 미래를 위해 의존성을 낮추고 싶어 clock_evict_policy() 함수를 새로 구현했다.
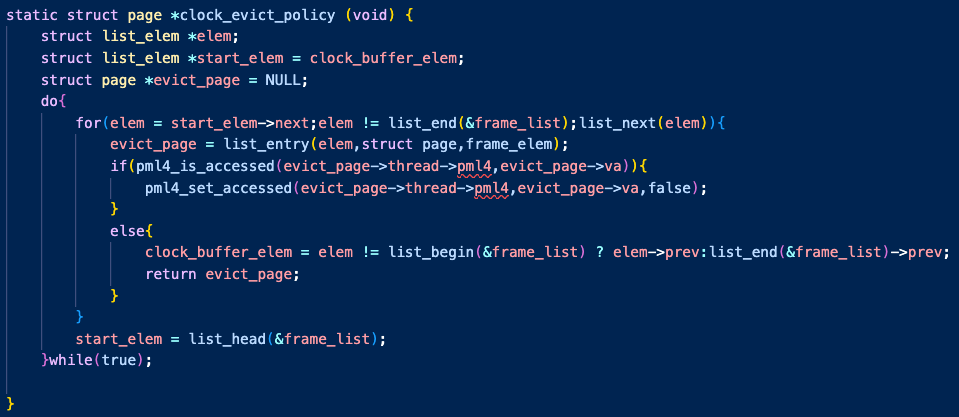
이 함수가 본격적으로 frame을 순회하며 퇴거정책을 수행하는 코드이다.
clock 퇴거 정책이 LRU와 비슷한 효율을 낸다는 것을 듣고 구현해보려 했다.
완전히 동일하게 구현한 것은 아니지만, 가장 최근에 들어온 프레임의 다음부터 한바퀴 순회하며 accessed 비트를 검사했다.
이때, 고민했던 부분이 한가지 있는데,
"프레임은 모든 프로세스의 공용 공간이므로 서로 다른 프로세스의 페이지들이 존재한다.
따라서 이를 순회할때 accessed 비트를 확인할때는
확인하는 페이지의 pml4를 통해 accessed 비트를 확인해야 하지 않나?"
였다.
그래서 생각해 낸 방법이 page struct 안에 그 페이지의 주인 thread를 기억하게 하는 것이었다.
지금 생각해보면 직접 pml4를 기억시키는 방법도 있었을 것 같다. 그 때는 각기 다른 thread를 어떻게 기억하지? 라고 생각한 것에서 나온 방법이었다.
무튼 clock_evict_policy 함수로 돌아오면 frame 리스트를 순회하며 (이 프레임 리스트엔 페이지가 swap_in 될 경우 삽입된다.)
최근에 접근한 페이지는 한번 넘어가주고, 접근하지 않은 페이지를 evict하도록 설계했다.
그렇게 퇴거될 프레임이 선정되면 이 프레임은 각 타입에 맞게 swap_out되고,
비게 된 프레임은 페이지폴트를 요청한 페이지가 저장될 수 있게 kva를 전달하고 새 페이지와 연결했다.
이때, swap_in과 swap_out의 수행 작업은 각 페이지 유형별로 다른데
swap_in만 보자면 총 3가지가 있다.
1. 아직 로드되지 않은 페이지 (uninit)
2. 이전에 로드되어 anon 페이지인데 퇴거되어 swap에 있는 페이지 (anon)
3. 이전에 mmap으로 로드되어 file 페이지 인데 퇴거되어 disk에 있는 페이지 (file)
따라서 각 swap_in 과 swap_out 함수는 유형별로 다르게 처리해야 하는데
이를 java의 상속 개념을 사용하면 편리하겠지만
C에서는 상속이 없으므로 핀토스에서는 이를 함수 포인터를 이용하여 다음 코드와 같이 define 매크로를 사용하여 처리한다.
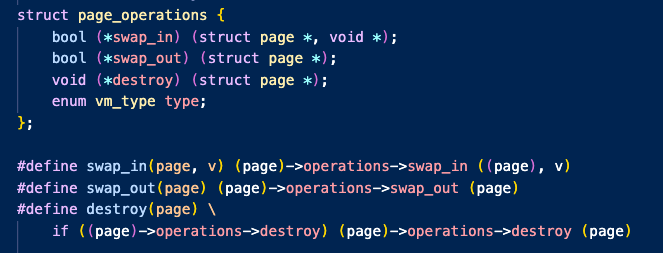
따라서 각 유형별로 swap_in , swap_out , destroy를 구현해야 했다.
file과 anon은 다음 포스팅에서 mmap과 swap 구현의 내용에 참조하겠다.
이번 포스팅에서는 lazy_load 과정만 살펴볼 것이므로 uninit이 swap_in되는 과정을 살펴보자.
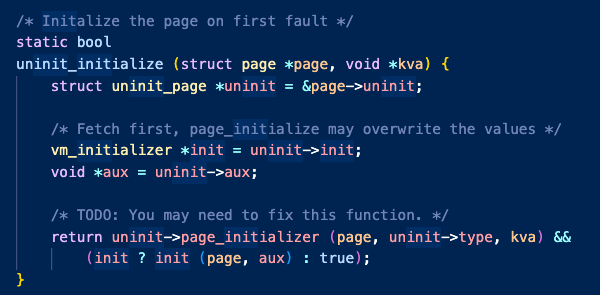
이 함수를 통해 요청받은 uninit 페이지는 이제 실제 물리 메모리에 적재되었으므로 page_initializer를 통해 anon으로 전환하고, 이전에 기억했던 lazy_load함수에 인자를 전달해서 실행한다.
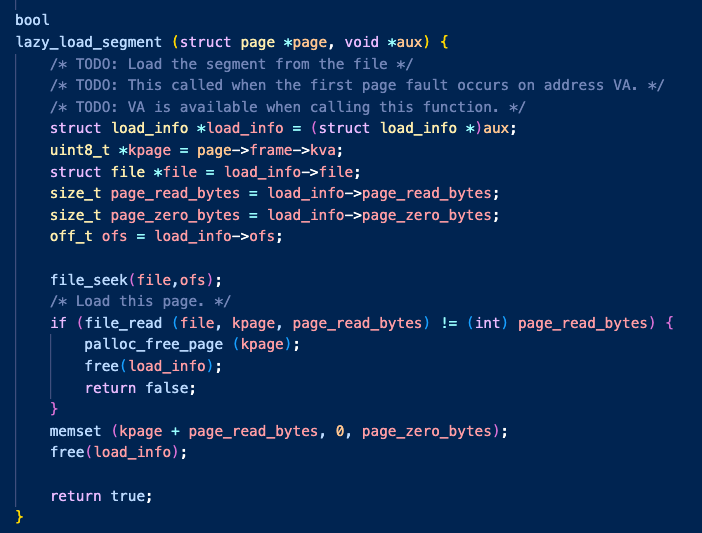
마지막으로 lazy_load_segment() 함수를 살펴보자.
이 함수를 통해 이전에 전달했던 load_info를 사용하여 file을 읽고 kpage에 쓴다.
이후 load_info는 필요없으므로 free()하여 메모리 누수를 방지했다.
이렇게 lazy_loading 을 통해 메모리를 가상화했고, 마치 컴퓨터의 실행되는 프로세스는 자신이 모든 물리메모리를 달라는 만큼 사용할 수 있는 것처럼 수행되도록 했다.
VM의 구조 상 포스팅 할 양이 많았다.
이후 mmap/munmap을 통한 메모리 매핑 페이지의 할당과 반환을 구현한 것을 포함하여
swap과 spt fork는 어떻게 수행했는지 포스팅하겠다.
'Jungle' 카테고리의 다른 글
| [TIL] 리버스 프록시(Reverse Proxy) 개념 (1) | 2023.12.30 |
|---|---|
| [TIL] pintos : 가상 메모리 구현 (2) - fork , mmap , swap (1) | 2023.12.29 |
| [TIL] pintos : mmap 트러블 슈팅 (1) | 2023.12.26 |
| [TIL] pintos : stack growth 지원하기 (1) | 2023.12.23 |
| [TIL] pintos : VM - fork uninit 시 aux도 복사해주기 (1) | 2023.12.23 |